type
status
date
slug
summary
tags
category
icon
password
1. 背景
- spring + k8s,java8
- 现象:某个pod总是触发系统的oom-killer机制,如果流量大,oom来的快,流量小,oom来的就晚。但是spring boot admin显示heap和non-heap很正常,gc正常
下面是运维角度的排查,供参考
2. 排查方向
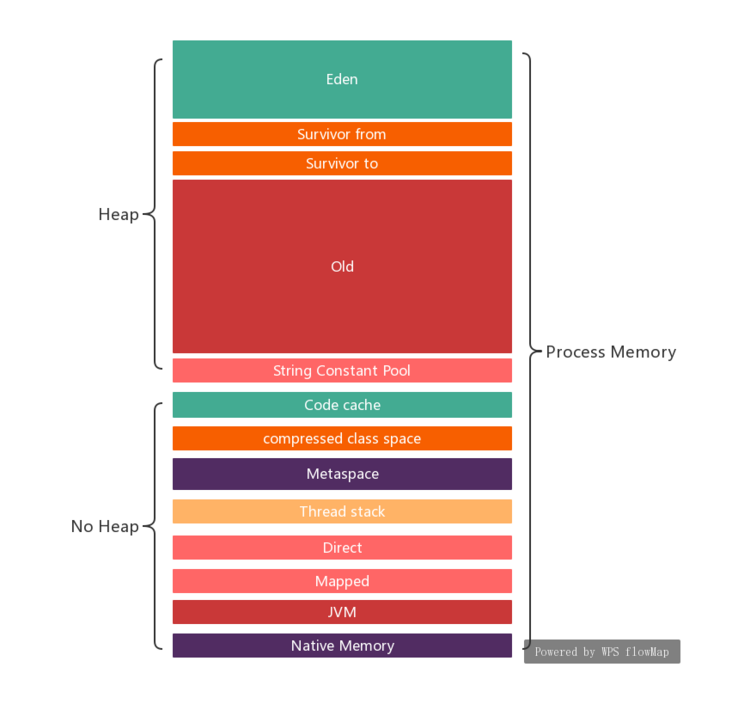
jvm的内存构成分析满大街,下面是一个参考。不过“堆外内存”这个概念有点绕,比如本次涉及的DirectByteBuffer,不属于堆,貌似也不属于non-heap,因为在spring boot监控里面看不到对应的值。
2.1. 系统的oom-killer原因
container_memory_working_set_bytes 是判断依据,然后根据容器的/proc/$pid/oom_score 排序,分数越高,死的越快
2.2. pod的内存为啥不断上涨?
检查容器配置,发现配置了-Xmx,没有开启容器感知cgroup的配置,故对于服务来说,它看到的资源是整个宿主机的。
先不用定量分析是谁占用了大量内存,定性分析可知开启cgroup至少可以缓解oom。
- 验证步骤:开启cgroup感知,百分比的设置是根据目前heap的峰值和cgroup limit值确定的,这个需要根据业务来适配
JVM_ARGS=-XX:+UseContainerSupport -XX:InitialRAMPercentage=70.0 -XX:MaxRAMPercentage=70.0 -XX:+PrintGCDetails -XX:+PrintGCDateStamps
- 验证结果:pod的内存上涨曲率显著变小。压测,曲率变大,停止压测,曲率变小。作为对比,按之前未感知cgroup的配置,即使压力少一半的情况下,pod很快就oom了,说明感知cgroup之后推迟了oom。
2.2. 寻找“隐藏的”jvm内存泄露点
非java开发,没法直接定量打印各种内存值。网上搜到一个分析jvm定量关系的表,有一定参考价值,特别是部分默认值的设定:

目前最大的怀疑对象就是MaxDirectMemorySize,因为在上一步并未显式配置,理论上它和Xmx一样大。简单计算:oom之后,pod内存第一次平稳的时候占比约45%(含heap,线程,Metaspace等),即45%是heap+部分non-heap的内存占比。由于Xmx=70%,故MaxDirectMemorySize是70%,45%+70%>100%
2.3. 还可以排查的方向
- 找研发定量分析,找出具体的故障点,研发不一定愿意做。由于现象是部分内存不回收,侧面找服务相关的中间件等监控,发现mongo的连接数趋势和pod内存趋势正相关,且都是established,可能是异常之后服务没有主动关闭连接。
- 增大pod的limit或者显式设置MaxDirectMemorySize,确保总内存不超出cgroup,理论上配置后DirectMemorySize达到阈值触发gc。既然服务不主动关闭连接,那让jvm的gc帮它体面。当然,如果猜想错误,那只能靠研发定量排查代码逻辑,或者扩大cgroup后躺平,推迟oom的到来。